J’ai récemment eu un problème de C++ suffisamment rare et dont la solution est suffisamment élégante pour que je pense utile de la partager dans un post de blog.
Je dispose d’un certain nombre de fonctions prenant des « scalaires » (un entier, un float, etc) et renvoyant un autre scalaire.
double add(double x, double y) {
return x + y;
}Je dispose également d’un type vectoriel contenant un certain nombre (connu à la compilation) de ces scalaires, l’équivalent d’un std::array
template<typename T, size_t N>
struct myvect {
T data[N];
};
La problématique était de pouvoir appliquer la fonction scalaire sur chacune des composants de vecteurs pour renvoyer un nouveau vecteur.
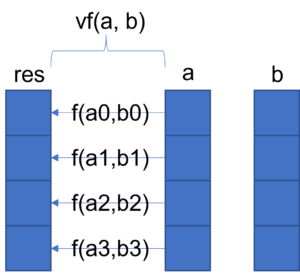
La solution naïve, dans le cas présenté au dessus, serait d’ajouter une fonction :
using Vd4 = myvect<double, 4>
Vd4 vadd(const Vd4 & va, const Vd4 & vb) {
Vd4 res;
for(int i = 0; i < 4; ++i) {
res.data[i] = add(va.data[i], vb.data[i]);
}
return res;
}Mais pour chaque fonction scalaire, je devrai rajouter une nouvelle fonction vectorielle, ce qui est déjà long et fastidieux, et impossible si l'utilisateur peut définir ses propres fonctions scalaires.
L'idée est donc de généraliser, autant que possible, la génération de fonctions "vectorielles" à partir de fonctions "scalaires", le tout en gardant des performances optimales.
Problème : je dispose d'énormément de fonctions, elles peuvent prendre plusieurs types d'arguments, et prendre un nombre quelconque d'arguments. Les fonctions peuvent être définies par l'utilisateur (mais restent connues à la compilation).
Qui dit connu à la compilation dit template, et qui dit nombre quelconque d'arguments dit variadic templates.
Partons sur un type de vecteur simple :
template<typename T>
struct myvect {
T data[4];
};On voudrait maintenant pouvoir écrire quelque chose comme ça :
template<typename retS, typename... args>
myvect<retS> func_vec(myvect<args>... vecs) {
myvect<retS> res; // initialized somehow
for (int i = 0; i < 4; ++i) {
res.data[i] = func_scalar(/* ?? */);
}
return res;
}Le problème est qu'on a besoin d'invoquer func_scalar sur une tranche (slice) (à l'index i) des vecteurs vecs. C'est là que std::integer_sequence vient à notre secours. On peut écrire une petite structure intermédiaire et une fonction qui nous renvoie cette tranche au bon index :
template<typename... Ts>
struct slice_helper {
template<std::size_t... I>
static auto inner(int index, std::tuple<myvect<Ts>...> vects, std::index_sequence<I...>)
{
return std::make_tuple(std::get<I>(vects).data[index]...);
}
};
template<typename... Ts>
auto slice(int index, std::tuple<myvect<Ts>...> vectors)
{
return slice_helper<Ts...>::template inner(index, vectors, std::index_sequence_for<Ts...>{});
}En utilisant cette fonction, on peut alors écrire la fonction vectorize qui prend une fonction en argument. Notons qu'on fait appel à std::apply qui permet d'invoquer un pointeur de fonction sur un tuple d'arguments.
template<typename retS, typename... args>
struct vectorize {
template<retS(*funcptr)(args...)>
static myvect<retS> func_vect(myvect<args>... v) {
myvect<retS> res;
auto tuple = std::make_tuple(v...);
for (int i = 0; i < 4; ++i) {
res.data[i] = std::apply(funcptr, slice(i, tuple));
}
return res;
}
};Ceci peut alors s'invoquer comme cela :
int test(int a, int b) {
return a + b;
}
int main() {
myvect<int> a { 1, 2, 3, 4 };
myvect<int> b { 2, 4, 6, 8 };
auto added = vectorize<int, int, int>::func_vect<&test>(a, b);
for(int i = 0; i < 4; ++i) {
printf("%d\n", added.data[i]);
}
}Clang 14 génère alors l'assembleur suivant (où il a tout calculé à la compilation) :
main: # @main
pushq %rax
movl $.L.str, %edi
movl $3, %esi
xorl %eax, %eax
callq printf
movl $.L.str, %edi
movl $6, %esi
xorl %eax, %eax
callq printf
movl $.L.str, %edi
movl $9, %esi
xorl %eax, %eax
callq printf
movl $.L.str, %edi
movl $12, %esi
xorl %eax, %eax
callq printf
xorl %eax, %eax
popq %rcx
retq
.L.str:
.asciz "%d\n"
Avec quelques menues modifications, il est possible de prendre des vecteurs de longueur quelconque (mais connue à la compilation).
Toutefois, en cherchant à optimiser encore le code, il m'est apparu que la boucle sur les tranches n'est pas vectorisée (au sens des instructions avx/avx2/avx512). Je retrouvais une boucle dans l'assembleur, avec des chargements mémoires non alignés et des additions scalaires. Cela est dû à deux problèmes :
- cette boucle est une boucle runtime et pas une boucle compile time (ce qui est possible à réaliser puisque la taille est connue à la compilation).
- la structure myvect n'est pas alignée comme il faut
De même, pour un export vers une librairie, il s'agissait de s'abstraire du type myvect pour prendre n'importe quel type de vecteur.
Pour écrire une boucle compile-time, il me fallait d'abord des opérateurs d'accès mémoire template. De même, pour l'alignement, il fallait rajouter un attribut. Le vecteur réécrit est donc de la forme :
#ifdef _MSC_VER
#define ALIGNED(x) __declspec(align(x))
#define INLINED __forceinline inline
#else
#define ALIGNED(x) __attribute__((aligned(x)))
#define INLINED __attribute__((always_inline))
#endif
template<typename T, size_t N>
struct ALIGNED(64) myvect {
T data[N];
template<int index>
T get() const {
return data[index];
}
template<int index>
void set(const T& v) {
data[index] = v;
}
};
La fonction slice peut se réécrire pour accepter n'importe quel type de vecteur avec la même signature template :
template<template <typename, size_t> class V, size_t N, typename... Ts>
struct slice_helper {
template<size_t index, std::size_t... I>
static auto inner(std::tuple<const V<Ts, N>&...> vects, std::index_sequence<I...>)
{
return std::make_tuple(std::get<I>(vects).template get<index>()...);
}
};
template<size_t index, template<typename, size_t> class V, size_t N, typename... Ts>
auto slice(const V<Ts, N>&... vectors)
{
return slice_helper<V, N, Ts...>::template inner<index>(std::make_tuple(vectors...), std::index_sequence_for<Ts...>{});
}
De la même façon, nous pouvons définir une structure déroulant la boucle à la compilation :
template<size_t index, template<typename, size_t> class V, size_t N, typename retS, typename... args>
struct loop_apply_helper {
template<retS(*funcptr)(args...)>
struct inner {
INLINED
static void apply(V<retS, N>& res, const V<args, N>&... v) {
res.template set<index>(std::apply(funcptr, slice<index>(v...)));
loop_apply_helper<index + 1, V, N, retS, args...>::template inner<funcptr>::apply(res, v...);
}
};
};
// partial specialization for end of loop
template<template<typename, size_t> class V, size_t N, typename retS, typename... args>
struct loop_apply_helper<N, V, N, retS, args...> {
template<retS(*funcptr)(args...)>
struct inner {
INLINED
static void apply(V<retS, N>& res, const V<args, N>&... v) {
}
};
};
Avec ces éléments, la fonction vectorize peut alors se réécrire d'une façon plus générique et performance :
template<template<typename, size_t> class V, size_t N, typename retS, typename... args>
struct vectorize {
template<retS(*funcptr)(args...)>
INLINED
static V<retS, N> func_vect(const V<args, N>&... v) {
V<retS, N> res;
loop_apply_helper<0, V, N, retS, args...>::template inner<funcptr>::apply(res, v...);
return res;
}
};
Il est temps de passer à un test :
double fmadd(double a, double b, double c) {
// fused multiply add (should run in only one micro-op)
return a * b + c;
}
using V = myvect<double, 32>
V vfmadd(const V& a, const V& b, const V& c) {
return vectorize<myvect, 32, double, double, double, double>::func_vect<&fmadd>(a, b, c);
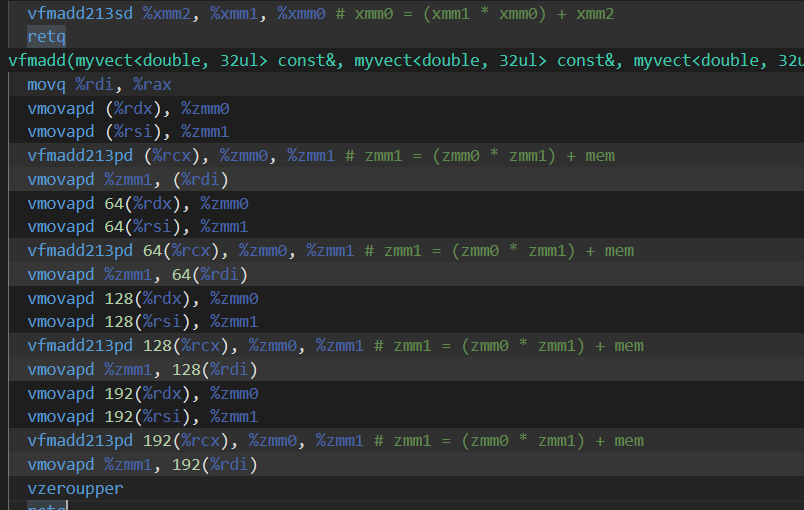
}And now, clang 14 with appropriate options (-O3 -std=c++20 -mavx512f) generates the following assembly :
fmadd(double, double, double): # @fmadd(double, double, double)
vfmadd213sd %xmm2, %xmm1, %xmm0 # xmm0 = (xmm1 * xmm0) + xmm2
retq
vfmadd(...)
movq %rdi, %rax
vmovapd (%rdx), %zmm0
vmovapd (%rsi), %zmm1
vfmadd213pd (%rcx), %zmm0, %zmm1 # zmm1 = (zmm0 * zmm1) + mem
vmovapd %zmm1, (%rdi)
vmovapd 64(%rdx), %zmm0
vmovapd 64(%rsi), %zmm1
vfmadd213pd 64(%rcx), %zmm0, %zmm1 # zmm1 = (zmm0 * zmm1) + mem
vmovapd %zmm1, 64(%rdi)
vmovapd 128(%rdx), %zmm0
vmovapd 128(%rsi), %zmm1
vfmadd213pd 128(%rcx), %zmm0, %zmm1 # zmm1 = (zmm0 * zmm1) + mem
vmovapd %zmm1, 128(%rdi)
vmovapd 192(%rdx), %zmm0
vmovapd 192(%rsi), %zmm1
vfmadd213pd 192(%rcx), %zmm0, %zmm1 # zmm1 = (zmm0 * zmm1) + mem
vmovapd %zmm1, 192(%rdi)
vzeroupper
retq
où nous pouvons voir les instructions vmovapd (chargement de 512 bits -- groupés en 8 flottants double précision) et vfmadd213pd (fused multiply add on 512 bits registers).
Le code complet est disponible ici :